Syllabify
I’ve been trying to write more. Not for any particular reason – just this vague notion that writing makes you better at thinking, and I’d like to be better at thinking. My problem is I can never get started. So naturally I’m starting with haiku, because 17 syllables is the minimum viable amount of writing, and I respect that.
Except then I needed to check my syllable counts, and that’s where things went sideways. I just needed to change a light bulb, and three hours later I was elbow-deep in the wall rewiring the whole circuit. I needed to count to 17, so naturally I trained a transformer, ran a hyperparameter sweep, and wrote an Emacs package.
The problem
Counting syllables is surprisingly annoying to do programmatically. Rule-based approaches exist but they’re brittle: English pronunciation is irregular enough that any hand-written ruleset will have exceptions. The CMU Pronouncing Dictionary has ~134,000 words with phoneme-level transcriptions, which means you can count syllables exactly by counting vowel nuclei in the arpabet phoneme set. That makes it a good supervised learning target: clean labels, large dataset, and well-defined task.
The model
It’s a character-level transformer classifier. You feed it a word as a sequence of characters, it outputs a predicted syllable count from 1-10.
Input encoding: Each character maps to an integer index. The vocabulary is a-z plus some metacharacters (hyphen, apostrophe, pad, and unk), 30 tokens total. Words are padded or truncated to 30 characters. Character embeddings (learned) are summed with positional embeddings (also learned).
Architecture: A standard transformer encoder stack. Each layer has multi-head self-attention followed by a feedforward block with pre-norm (layernorm before attention rather than after). The output is mean-pooled over non-padded positions, then passed through a linear classification head.
Final design:
vocab size: 30 tokens
embedding dim: 256
attention heads: 8
layers: 4
feedforward dim: 2048
dropout: 0.1
max length: 30 characters
output classes: 10 (syllable counts 1–10)
parameters: ~5.3M
Training: AdamW optimizer, lr=3e-4 with cosine annealing, batch size 512, 30 epochs. Trained on 90% of the CMU dict (~120k words), validated on the remaining 10%.
The data
data/prepare.py downloads the CMU Pronouncing Dictionary directly from GitHub, parses it, counts vowel nuclei per word (arpabet vowels end in a stress digit 0/1/2, so it’s just a regex match), and writes tab-separated word/count pairs to train.txt and val.txt. Alternate pronunciations are discarded. Words with non-alphabetic characters other than hyphens and apostrophes are filtered out.
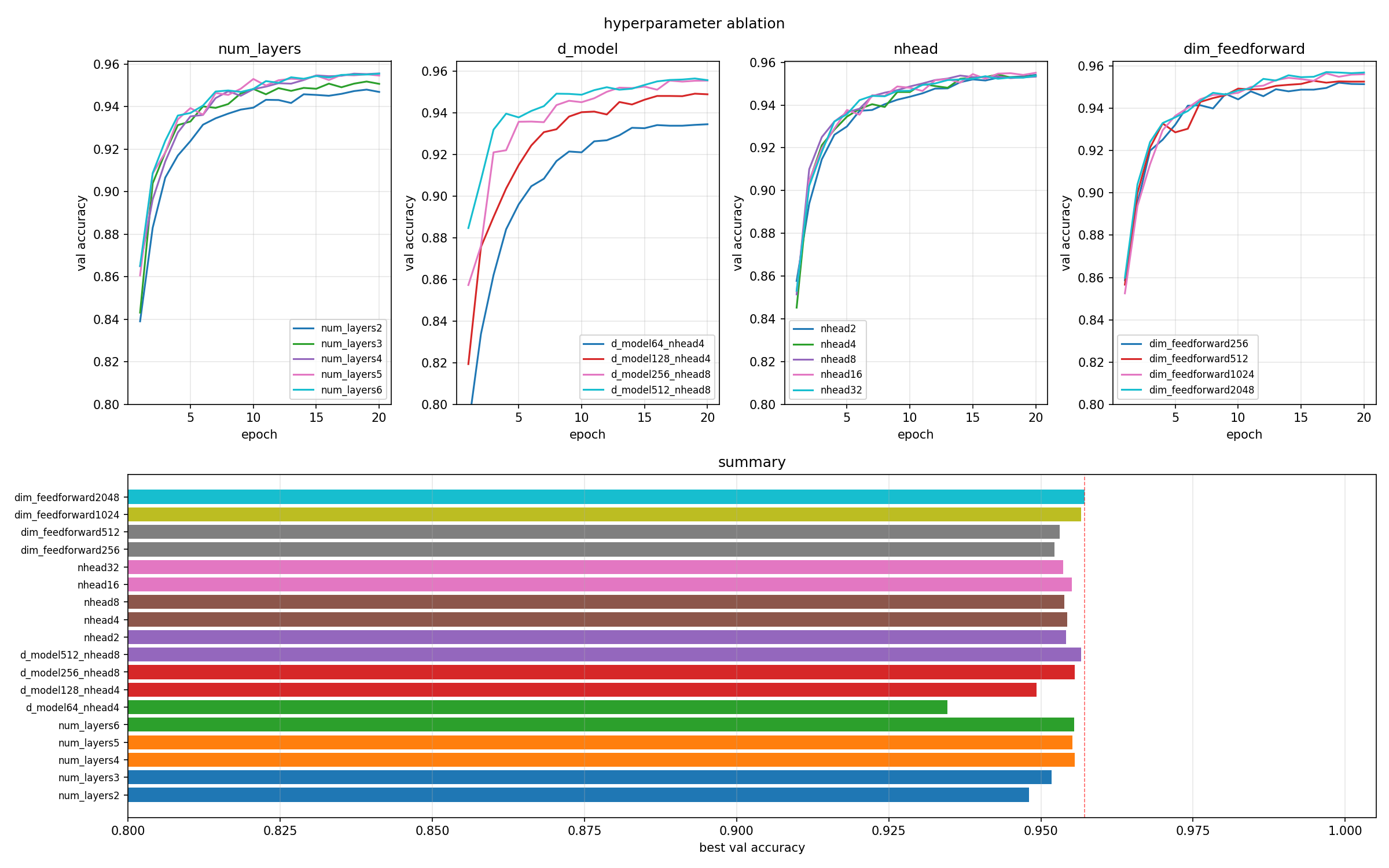
Hyperparameter ablation
This is the part where the light bulb replacement turned into a full electrical inspection. I ran an ablation study varying four architectural parameters independently, holding everything else at the baseline config. Each run was 20 epochs, ~18 runs total, about 30 minutes on a decent GPU.
num_layers (2, 3, 4, 5, 6): 4 layers is the sweet spot. Adding more layers past 4 essentially gives no improvement (95.56% -> 95.52% -> 95.55%) while adding ~800k parameters per layer. 2 layers is noticeably worse at 94.80%.
d_model (64, 128, 256, 512): The biggest lever. d_model=64 only reaches 93.46%, while 256 hits 95.56%. d_model=512 ekes out 95.66% but nearly triples the parameter count (8.4M vs 3.2M). Not worth it.
nhead (2, 4, 8, 16, 32): Completely flat. All values cluster between 95.37-95.51% with identical parameter counts. The model doesn’t care how you partition the attention heads for this task. This makes sense: syllable counting depends on local character patterns (suffixes, vowel clusters) more than long-range dependencies, so the specifics of attention head factoring don’t matter much.
dim_feedforward (256, 512, 1024, 2048): Clean monotonic improvement. 256 (95.22%) -> 512 (95.31%) -> 1024 (95.66%) -> 2048 (95.72%). 2048 wins, and the parameter cost is reasonable (5.3M vs 3.2M for 1024).
Conclusion: Bump dim_feedforward to 2048, keep everything else. The final model hits 95.74% validation accuracy on the CMU dict held-out set. The remaining ~4.3% errors are mostly genuinely hard cases: borrowed words with unexpected stress patterns, proper nouns, abbreviations – things that a human would also need context for.
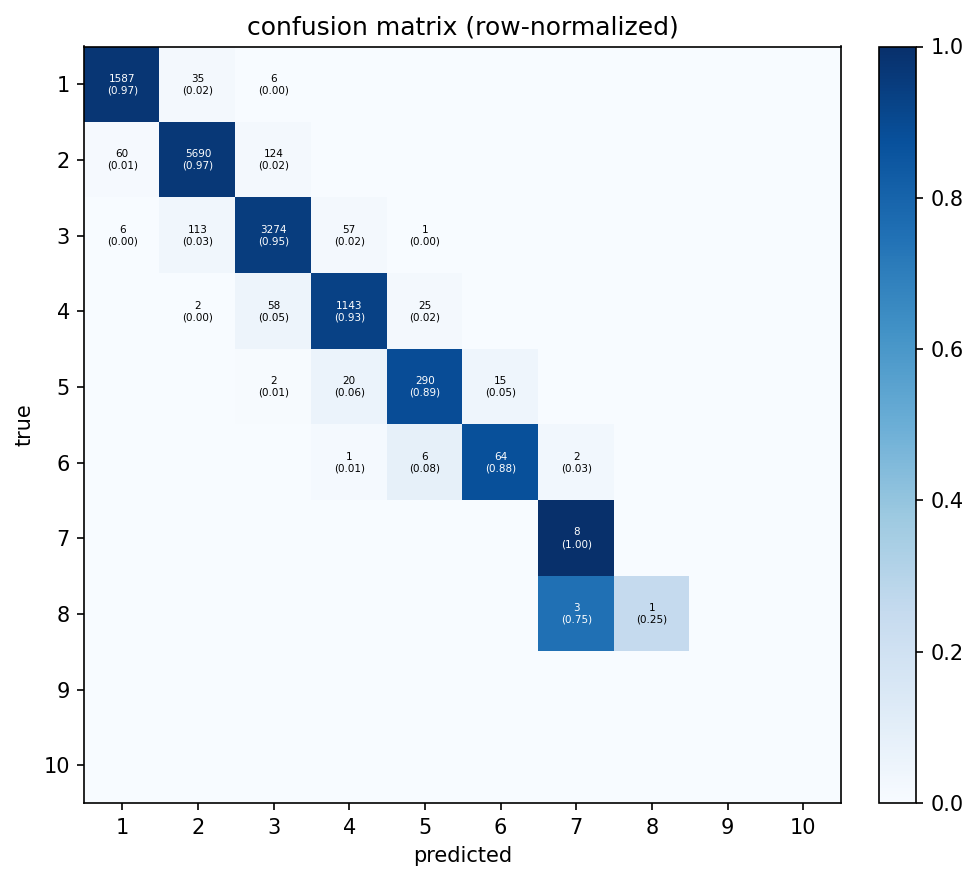
Confusion matrix: Errors are almost entirely off-by-one. The model rarely jumps two counts away, which makes sense: if it’s wrong, it’s usually because a word looks like it has one more or fewer syllable than it does. Rows 7–10 are sparse enough that the per-cell numbers aren’t meaningful; there just aren’t many 7+ syllable words in the validation set.
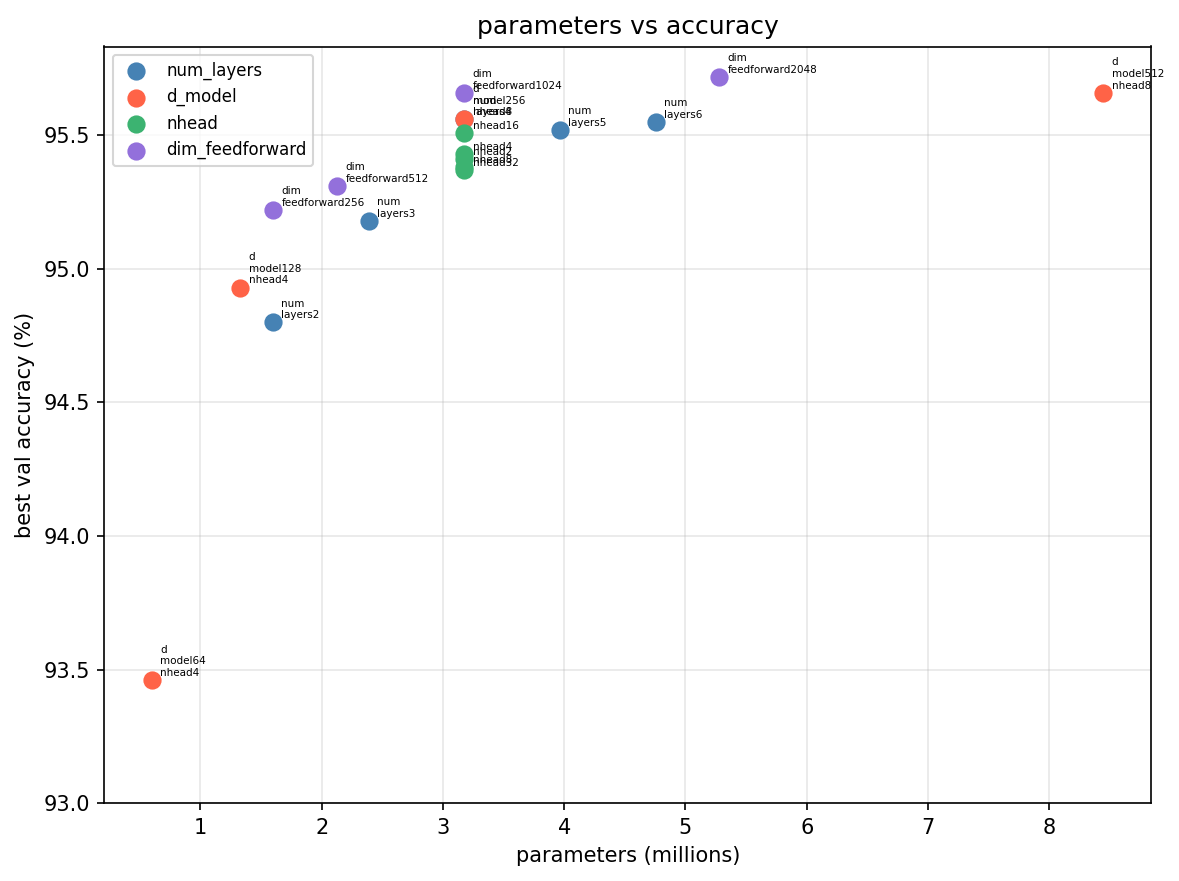
Parameters vs accuracy: d_model is the most important knob: d_model=64 lands at 93.5% while d_model=512 pushes to 95.7%, a real gap across a 10× parameter increase. nhead is the flattest cluster on the chart — all values sit at 95.4–95.5% with nearly identical parameter counts, confirming it doesn’t matter how you partition the attention heads for this task. dim_feedforward shows clean monotonic improvement and num_layers shows 2 is noticeably bad, but 3–6 are hard to tell apart.
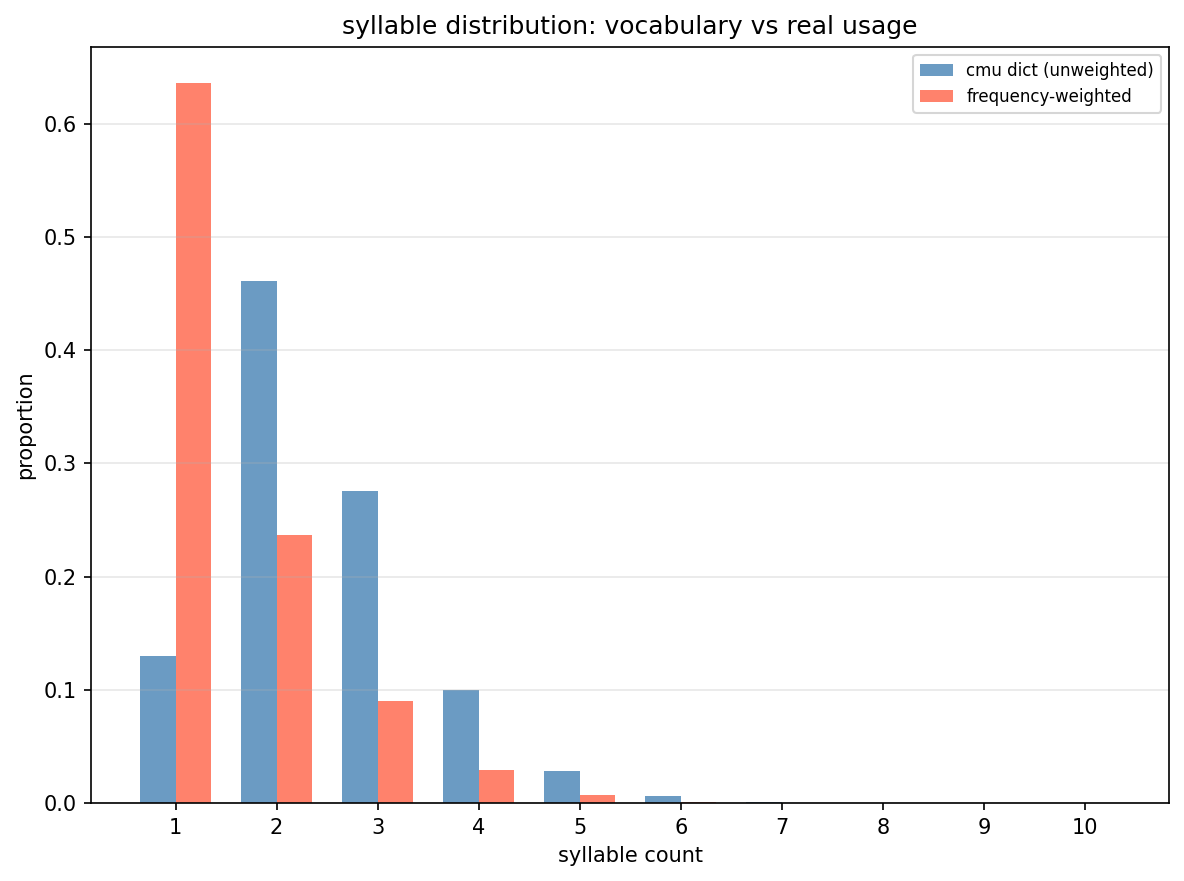
Syllable distribution: The unweighted CMU dict peaks at 2-syllable words (~46%), but when you weight by how often words actually appear in English text, 1-syllable words dominate at ~64%. Short function words (“the”, “a”, “is”, “have”) are used constantly, while the long polysyllabic vocabulary entries sit mostly unused. The model trains on the unweighted distribution, which is worth keeping in mind for its real-world accuracy profile.
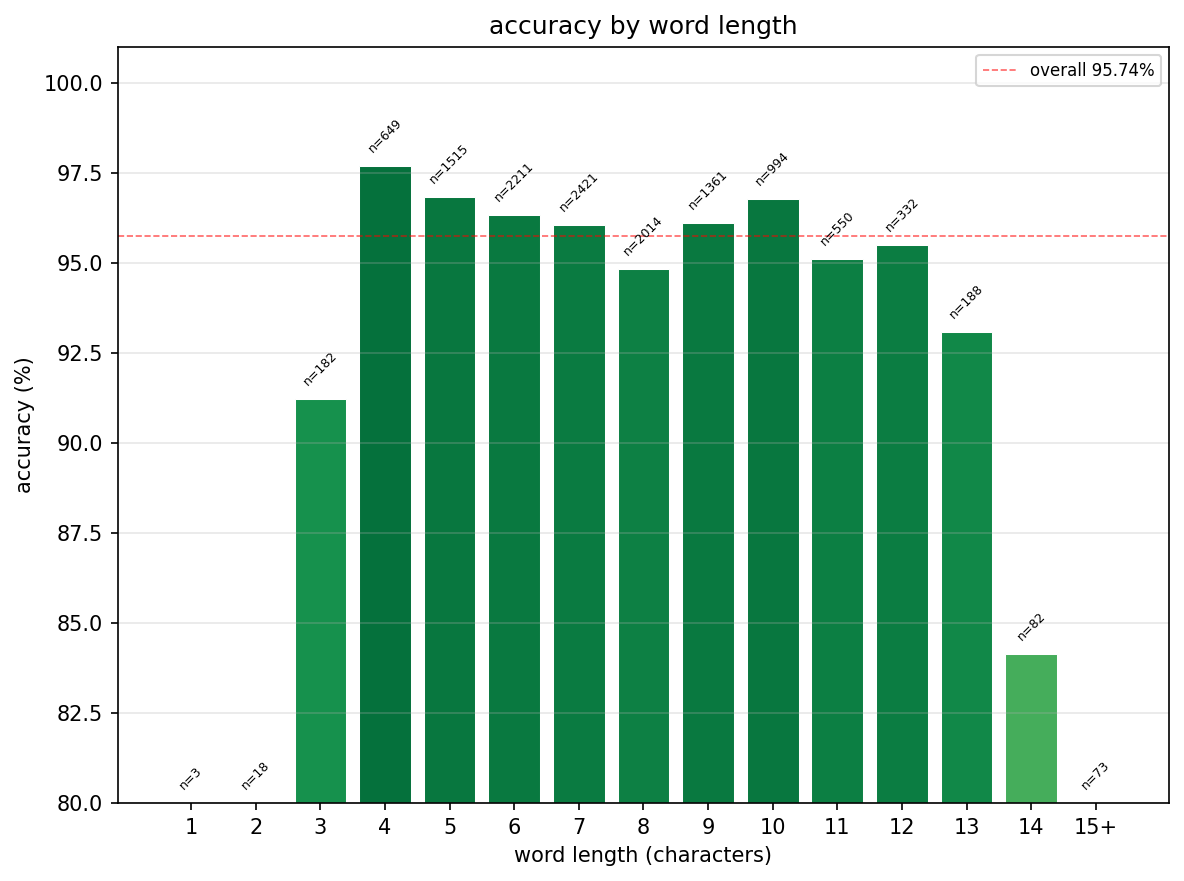
Accuracy by word length: The model is strongest on 4–5 character words (~97–98%) and holds above 95% for most of the range. it dips at length 3 (~91%), probably because very short words are disproportionately irregular. It falls to ~84% for 14+ character words, where training examples get sparse and the fixed 30-character context is less of an advantage.
The Emacs package
Having trained the model, the obviously necessary next step (see: xkcd 1319) was to wire it into emacs so syllable counts appear in the left margin while you write. This is genuinely useful for haiku. It is also 140 lines of emacs lisp for a problem that could have been solved by counting on your fingers.
It works by running a persistent python server process in the background: the model loads once, then the server reads batches of lines from stdin and writes counts back. This keeps inference latency low enough to be usable in real time.
The server uses a simple line protocol: send a batch of lines, terminate with <<<END>>>, receive one integer per line back, terminated with <<<END>>>. The sentinel needed to be something that wouldn’t appear in markdown files; --- was the obvious first choice and caused a bug immediately because yaml front matter uses it everywhere.
The Emacs side debounces text changes at 300ms, sends the full buffer on each update, and displays results as overlays in a 3-character left margin column. It only activates in modes listed in syllabify-modes (default: markdown-mode, text-mode).
To use it:
(use-package syllabify
:load-path "~/path/to/syllabify/emacs"
:config (global-syllabify-mode 1))
You need a trained checkpoint at checkpoints/best.pt. The server starts automatically when you open a buffer in a matching mode.
Was it worth it?
Probably not. But I learned something, the model works, and the haiku I was trying to write is still bad for reasons unrelated to syllable counts. Sometimes that’s enough.
Code
The whole thing is at github.com/hipml/syllabify. ~300 lines of python, ~140 lines of emacs lisp.